
Page 338 - Special Topic Session (STS) - Volume 2
P. 338
STS497 Maria D.M.P.
Data Cleaning. The Tax data originally had a total of 40,038 records and
20 fields. Fields that are only 0%-50% populated were deleted; decreasing the
number of fields to 17. The Company Registry data originally had a total of
219 records and 143 fields. Fields that are only 0%-50% populated were
deleted and information in date format (DAY/MONTH/YEAR) were separated
into date day, date month and date year; decreasing the number of fields to
29. For both datasets, all strings were capitalized, abbreviations were
elongated, and unnecessary punctuations and extra spaces were removed.
Deduplication with a Dataset. Finding potential duplicates within
datasets can only be done in RStudio. The tax data was split into eight sections
(5,000 records per file) due to the processing limit of the hardware. There will
be two rounds of deduplication. The first one will be within each dataset and
the second will be between each dataset. The blocking variables used for the
company registry data would be District and City. Business TIN, Business
Name, and Business Unit Name were used for comparison. 77 exact duplicates
were detected through deduplication, 72 within datasets and 5 between the
datasets. The new record count is now 39,961. The maximum match rate
(measure of similarity) is 1 for both the Levenshtein and Jarowinkler
algorithms. The minimum match rate for Jarowinkler vary between 0.111 to
0.194. For Levenshtein, the minimum match rate does not deviate from 0.833.
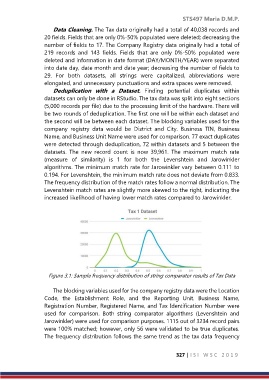
The frequency distribution of the match rates follow a normal distribution. The
Levenshtein match rates are slightly more skewed to the right, indicating the
increased likelihood of having lower match rates compared to Jarowinkler.
Figure 3.1: Sample frequency distribution of string comparator results of Tax Data
The blocking variables used for the company registry data were the Location
Code, the Establishment Role, and the Reporting Unit. Business Name,
Registration Number, Registered Name, and Tax Identification Number were
used for comparison. Both string comparator algorithms (Levenshtein and
Jarowinkler) were used for comparison purposes. 1115 out of 3234 record pairs
were 100% matched; however, only 56 were validated to be true duplicates.
The frequency distribution follows the same trend as the tax data frequency
327 | I S I W S C 2 0 1 9