
Page 24 - Contributed Paper Session (CPS) - Volume 5
P. 24
CPS649 A-Hadi N. Ahmed et al.
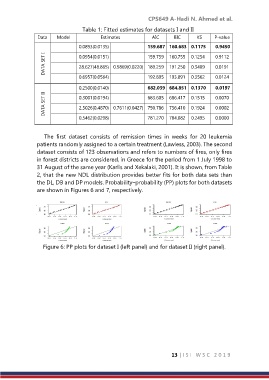
Table 1: Fitted estimates for datasets I and II
Data Model Estimates AIC BIC KS P-value
0.0893(0.0135) 159.687 160.683 0.1175 0.9450
DATA SET I 0.0954(0.0151) 159.759 160.755 0.1254 0.9112
0.0191
28.627(48.865) 0.9869(0.0220) 189.259 191.250 0.3409
0.6957(0.0564) 192.895 193.891 0.3562 0.0124
0.2500(0.0140) 682.039 684.851 0.1370 0.0197
DATA SET II 0.3001(0.0194) 683.605 686.417 0.1515 0.0070
2.5026(0.4870) 0.7611(0.0427) 750.786 756.410 0.1924
0.0002
0.5462(0.0298) 781.270 784.082 0.2495 0.0000
The first dataset consists of remission times in weeks for 20 leukemia
patients randomly assigned to a certain treatment (Lawless, 2003). The second
dataset consists of 123 observations and refers to numbers of fires, only fires
in forest districts are considered, in Greece for the period from 1 July 1998 to
31 August of the same year (Karlis and Xekalaki, 2001). It is shown, from Table
2, that the new NDL distribution provides better fits for both data sets than
the DL, DB and DP models. Probability–probability (PP) plots for both datasets
are shown in Figures 6 and 7, respectively.
Figure 6: PP plots for dataset I (left panel) and for dataset II (right panel).
13 | I S I W S C 2 0 1 9