
Page 468 - Invited Paper Session (IPS) - Volume 1
P. 468
IPS177 F. Ricciato et al.
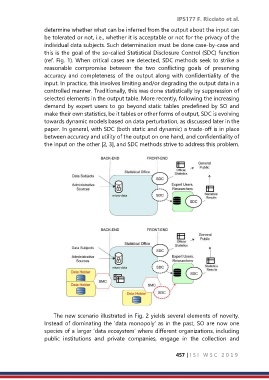
determine whether what can be inferred from the output about the input can
be tolerated or not, i.e., whether it is acceptable or not for the privacy of the
individual data subjects. Such determination must be done case-by-case and
this is the goal of the so-called Statistical Disclosure Control (SDC) function
(ref. Fig. 1). When critical cases are detected, SDC methods seek to strike a
reasonable compromise between the two conflicting goals of preserving
accuracy and completeness of the output along with confidentiality of the
input. In practice, this involves limiting and/or degrading the output data in a
controlled manner. Traditionally, this was done statistically by suppression of
selected elements in the output table. More recently, following the increasing
demand by expert users to go beyond static tables predefined by SO and
make their own statistics, be it tables or other forms of output, SDC is evolving
towards dynamic models based on data perturbation, as discussed later in the
paper. In general, with SDC (both static and dynamic) a trade-off is in place
between accuracy and utility of the output on one hand, and confidentiality of
the input on the other [2, 3], and SDC methods strive to address this problem.
The new scenario illustrated in Fig. 2 yields several elements of novelty.
Instead of dominating the ‘data monopoly’ as in the past, SO are now one
species of a larger ‘data ecosystem’ where different organizations, including
public institutions and private companies, engage in the collection and
457 | I S I W S C 2 0 1 9