
Page 87 - Contributed Paper Session (CPS) - Volume 4
P. 87
CPS2131 Philip L.H. Yu et al.
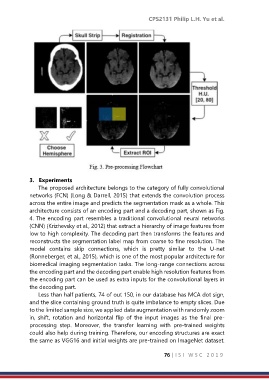
3. Experiments
The proposed architecture belongs to the category of fully convolutional
networks (FCN) (Long & Darrell, 2015) that extends the convolution process
across the entire image and predicts the segmentation mask as a whole. This
architecture consists of an encoding part and a decoding part, shown as Fig.
4. The encoding part resembles a traditional convolutional neural networks
(CNN) (Krizhevsky et al., 2012) that extract a hierarchy of image features from
low to high complexity. The decoding part then transforms the features and
reconstructs the segmentation label map from coarse to fine resolution. The
model contains skip connections, which is pretty similar to the U-net
(Ronneberger, et al., 2015), which is one of the most popular architecture for
biomedical imaging segmentation tasks. The long-range connections across
the encoding part and the decoding part enable high resolution features from
the encoding part can be used as extra inputs for the convolutional layers in
the decoding part.
Less than half patients, 74 of out 150, in our database has MCA dot sign,
and the slice containing ground truth is quite imbalance to empty slices. Due
to the limited sample size, we applied data augmentation with randomly zoom
in, shift, rotation and horizontal flip of the input images as the final pre-
processing step. Moreover, the transfer learning with pre-trained weights
could also help during training. Therefore, our encoding structures are exact
the same as VGG16 and initial weights are pre-trained on ImageNet dataset.
76 | I S I W S C 2 0 1 9